






Достижения в области искусственного интеллекта для анализа медицинских данных

Здравоохранение открыло эпоху преобразований, в которой доминируют искусственный интеллект и машинное обучение, которые теперь занимают центральное место в анализе данных и операционных утилитах.
Здравоохранение открыло эпоху преобразований, в которой доминируют искусственный интеллект (ИИ) и машинное обучение (МО), которые сейчас занимают центральное место в анализе данных и операционных утилитах. Преобразующая сила искусственного интеллекта и машинного обучения открывает беспрецедентную ценность за счет быстрого преобразования огромных наборов данных в практические идеи. Эти идеи по мнению разработчиков компании DST Global,не только улучшают уход за пациентами и оптимизируют процессы лечения, но и открывают путь к революционным медицинским открытиям. Благодаря точности и эффективности, обеспечиваемым искусственным интеллектом и машинным обучением, диагностика и стратегии лечения становятся значительно более точными и эффективными, ускоряя темпы медицинских исследований и знаменуя фундаментальный сдвиг в здравоохранении.
Преимущества ИИ в здравоохранении
Искусственный интеллект и машинное обучение будут влиять на всю экосистему отрасли здравоохранения. От более точных диагностических процедур до персонализированных рекомендаций по лечению и операционной эффективности — всего этого можно добиться с помощью искусственного интеллекта и машинного обучения. Технологии искусственного интеллекта помогают поставщикам медицинских услуг использовать возможности анализа данных в реальном времени, прогнозного анализа и поддержки принятия решений для наиболее активного и высоко персонализированного подхода к уходу за пациентами. Например, алгоритмы искусственного интеллекта повысят точность диагностики за счет изучения изображений, а модели машинного обучения помогут анализировать исторические данные, чтобы предсказать результаты лечения пациента, что позволит определить используемый подход к лечению.
Машинное обучение в анализе медицинских данных
Революция в данных о здоровье лежит на пороге машинного обучения с мощными инструментами, которые выявляют закономерности и прогнозируют будущие результаты на основе исторических данных. Первостепенное значение имеют алгоритмы, которые прогнозируют прогрессирование заболевания, улучшают методологии лечения и оптимизируют оказание медицинской помощи. Эти результаты позволят улучшить персонализированную медицину для разработки более эффективных стратегий замедления прогрессирования заболевания и улучшения ухода за пациентами. Самое главное, что алгоритмы машинного обучения оптимизируют операции в сфере здравоохранения посредством тщательного анализа данных о тенденциях, которые могут включать уровни госпитализации пациентов и использование ресурсов в оптимизированном рабочем процессе больницы, чтобы обеспечить более эффективное предоставление услуг.
Пример: уровень госпитализации пациентов со случайным лесом

Объяснение
- Загрузка данных: загрузите данные из файла CSV. Замените « Patient_data.csv» путем к вашему фактическому файлу данных.
- Выбор функций: выбираются только те функции, которые соответствуют целевым показателям госпитализации, например возраст, артериальное давление, частота сердечных сокращений и предыдущие госпитализации.
- Разделение данных: разделите данные на наборы обучения и тестирования, чтобы оценить производительность модели.
- Масштабирование признаков следует использовать для изменения масштаба признаков, чтобы модель учитывала все признаки одинаково, поскольку логистическая регрессия чувствительна к масштабированию признаков.
- Обучение модели: обучение модели логистической регрессии с использованием данных обучения.
- Попробуйте спрогнозировать поступление, используя модель из тестового набора.
- Оценка. Построенную модель следует оценить на основе точности, матрицы путаницы и подробного отчета о классификации из набора тестов для проверки прогноза модели для госпитализации пациентов.
Обработка естественного языка при анализе медицинских данных
Обработка естественного языка (NLP) — еще одна важная функция, позволяющая извлекать полезную информацию, включая клинические записи, отзывы пациентов и медицинские журналы. Инструменты НЛП помогают анализировать и интерпретировать огромное количество текстовых данных, ежедневно собираемых в медицинских учреждениях, тем самым облегчая доступ к соответствующей информации. Эта возможность очень важна для поддержки клинических решений и исследований, позволяя быстро получать информацию из существующих записей пациентов и литературы, повышая скорость и точность медицинской диагностики и ведения пациентов.
Пример: Модель глубокого обучения для обнаружения заболеваний при медицинской визуализации
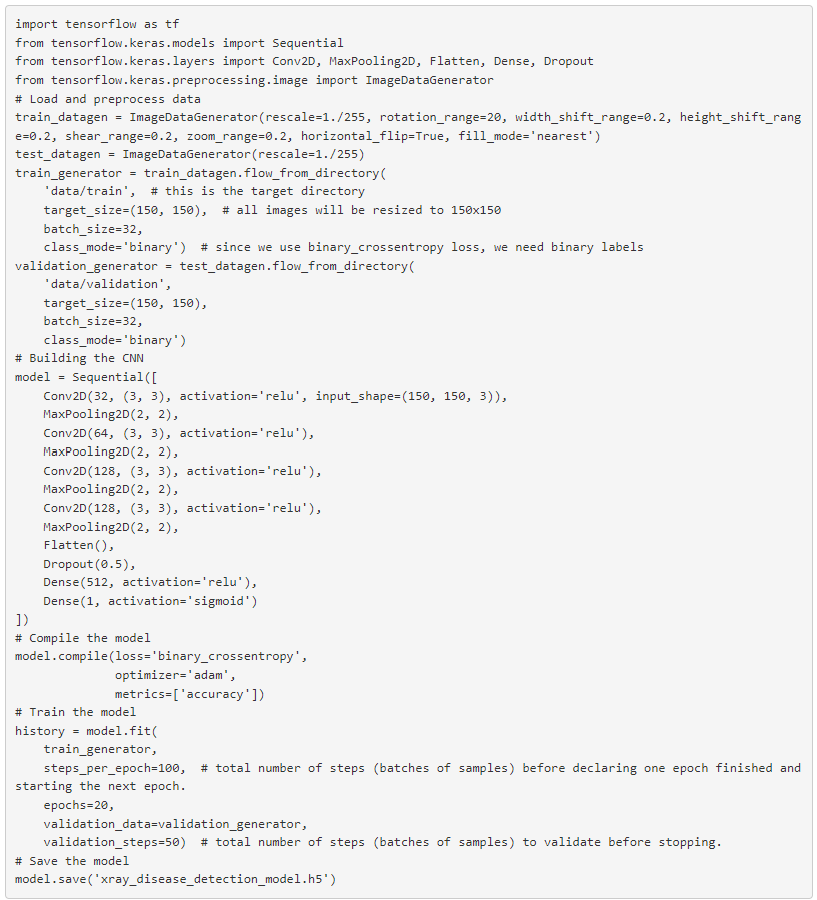
Объяснение
- ImageDataGenerator: автоматически настраивает данные изображения во время обучения для увеличения (например, поворот, сдвиг по ширине и высоте), что помогает модели лучше обобщать ограниченные данные.
- Flow_from_directory: загружает изображения непосредственно из структуры каталогов, изменяя их размер по мере необходимости и применяя преобразования, указанные в ImageDataGenerator.
- Архитектура модели . В модели последовательно используются несколько сверточных (Conv2D) и слоев пула (MaxPooling2D). Сверточные слои помогают модели изучить особенности изображений, а объединение слоев уменьшает размерность каждой карты объектов.
- Dropout: этот слой случайным образом устанавливает для части входных единиц значение 0 при каждом обновлении во время обучения, что помогает предотвратить переобучение.
- Сгладить: конвертирует объединенные карты объектов в один столбец, передаваемый в плотно связанные слои.
- Плотный: полностью связанные слои. Эти слои состоят из полностью связанных нейронов, которые получают входные данные от функций данных.
- Компиляция и обучение: модель компилируется с использованием двоичной функции кросс-энтропийных потерь, которая обычно подходит для этой задачи классификации. Затем он компилируется и оптимизируется с помощью данного оптимизатора и, наконец, обучается с использованием метода .fit на данных поезда, полученных от train_generator с проверкой с помощью validation_generator.
- Сохранение модели: сохраните обученную модель для дальнейшего использования, будь то для развертывания в медицинских диагностических приложениях или для дальнейшего уточнения.
Глубокое обучение в анализе медицинских данных
Глубокое обучение — это сложный предмет машинного обучения, используемый для анализа структур данных высокой сложности с использованием соответствующих нейронных сетей. Эта технология оказалась полезной в таких областях, как медицинская визуализация, где модели глубокого обучения эффективно обнаруживают и диагностируют заболевания по изображениям с уровнем точности, который иногда выше, чем у экспертов-людей. В геномике глубокое обучение помогает анализировать и понимать генетические последовательности, предлагая понимание, необходимое для анализа персонализированной медицины и планирования лечения.
Пример: глубокое обучение для классификации геномных последовательностей
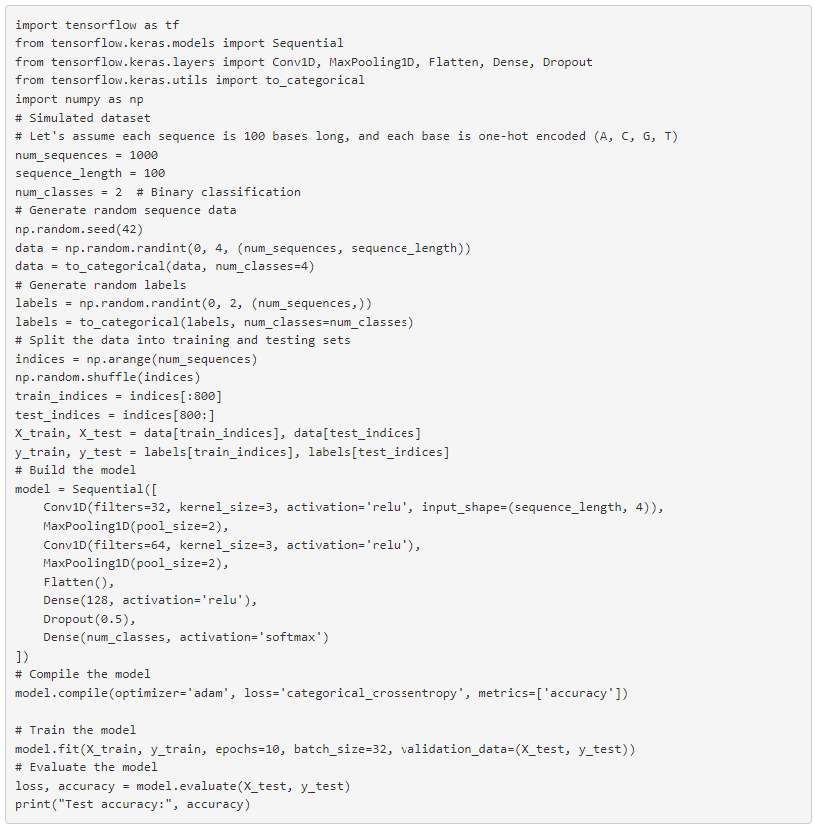
Объяснение
- Подготовка данных: мы моделируем данные последовательности, где каждое основание последовательности ДНК (A, C, G, T) представлено как вектор с горячим кодированием. Это означает, что каждая база преобразуется в вектор из четырех элементов. Последовательности и соответствующие метки (двоичная классификация) генерируются случайным образом для демонстрации.
- Архитектура модели и слои Conv1D. Эти сверточные слои особенно полезны для данных последовательностей (например, временных рядов или генетических последовательностей). Они обрабатывают данные таким образом, чтобы учитывать их временной или последовательный характер.
- Слои MaxPooling1D: эти слои уменьшают пространственный размер представления, уменьшая количество параметров и вычислений в сети и, следовательно, помогают предотвратить переобучение.
- Слой сглаживания: этот слой сглаживает выходные данные сверточных слоев и слоев объединения, которые будут использоваться в качестве входных данных для плотно связанных слоев.
- Плотные слои: это полностью связанные слои. Выпадение между этими слоями уменьшает переобучение, предотвращая сложную совместную адаптацию обучающих данных.
- Компиляция и обучение: Модель компилируется с помощью ' adam'оптимизатор и' categorical_crossentropy' функция потерь, типичная для задач многоклассовой классификации. Он обучается с использованием метода .fit, а производительность проверяется на отдельном наборе тестов.
- Оценка: после обучения производительность модели оценивается на тестовом наборе, чтобы увидеть, насколько хорошо она может обобщаться на новые, невидимые данные.
Применение искусственного интеллекта в диагностике и планировании лечения
ИИ значительно повысил скорость и точность диагностики заболеваний, используя медицинские изображения, генетические индикаторы и истории болезни для выявления самых незначительных признаков заболевания. Во-вторых, алгоритмы искусственного интеллекта помогают разрабатывать персонализированные схемы лечения, фильтруя огромные объемы данных о лечении и реакциях пациентов, чтобы обеспечить индивидуальный уход, оптимизируя терапевтическую эффективность и сводя к минимуму побочные эффекты.
Проблемы и этические соображения в области искусственного интеллекта и анализа данных о здоровье
Однако интеграция искусственного интеллекта и машинного обучения в здравоохранение по своей номинальной стоимости также сопряжена с этическими соображениями. Тем не менее, проблемными областями, требующими корректировки, являются конфиденциальность данных, алгоритмическая предвзятость и прозрачные процессы принятия решений, что указывает на важные ориентиры этих корректировок для надлежащего и ответственного использования ИИ в здравоохранении. Необходимо обеспечить безопасность и защиту данных пациентов, а любая установка должна гарантировать свободу от каких-либо предвзятостей и не терять доверия и справедливости при развертывании услуг.
Заключение
Будущее по мнению специалистов DST Global здравоохранения весьма многообещающее благодаря развитию технологий искусственного интеллекта и машинного обучения, которые обеспечивают новую изощренность спектра аналитических инструментов, таких как AR в хирургических процедурах и виртуальных медицинских помощников, работающих на базе ИИ. Эти достижения сделают возможным более качественную диагностику и лечение, обеспечивая при этом бесперебойную работу и, в конечном итоге, способствуя более индивидуальному и эффективному уходу за пациентами. По мере дальнейшего развития и непрерывной интеграции технологий искусственного интеллекта и машинного обучения оказание медицинских услуг изменится за счет более эффективного, точного и централизованного обслуживания пациентов. Это означает, что в дополнение к обсуждаемым бизнес- и техническим проблемам необходимо учитывать ряд нормативных ограничений.






