






Преимущества синтетических данных для тестирования, соответствия и генеративного ИИ

Примечательно, когда Microsoft и другие говорят о новых подходах и стандартах. Одним из примеров является то, как дифференциальная конфиденциальность и синтетические данные предпочитают для конфиденциальности и соблюдения данных. В этой статье разработчиками компании DST Global рассматривается, как используются синтетические данные, и преимущества, направляющие переход к синтетическим данным для конфиденциальности и соблюдения данных.
Смоделированные синтетические данные обеспечивают превосходную конфиденциальность данных
Microsoft и другие обращаются к синтетическим данным для превосходной конфиденциальности данных и удобства использования. Поскольку смоделированные синтетические данные могут выглядеть и вести себя как исходные данные, отражая распределение исходных данных. Полученный набор данных защищен конфиденциальностью и поддерживает точность, необходимую в инициативах машинного обучения и ИИ. Простая маскировка данных и анонимизация больше не считается наилучшей практикой.
Другим драйвером для синтетических данных является возникающий спрос на генеративный ИИ и необходимость в высоких объемах корпоративных текстовых данных для получения добычи из поиска (RAG). Поддержка билетов, документов Word и другие текстовые данные сканируются для идентификации личной информации (PII), которая либо отредактирована, либо заменена с помощью конфиденциальности, защищающих синтетические данные. Этот процесс создания озеро защищенного конфиденциальности является основополагающим для предприятий, занимающихся генеративными решениями искусственного интеллекта. Озеро Data проходит для создания авторитетного набора бизнес -знаний для поддержки извлечения дополненного поколения (RAG), что, в свою очередь, дополняет крупные языковые модели для решений искусственного интеллекта для бизнеса.
Синтетические данные для генеративного ИИ
Предприятия должны быть знакомы с требованиями конфиденциальности данных, такими как GDPR и Закон о конфиденциальности GDPR и Калифорнии, и защита информации в базах данных была легко доступна за последнее десятилетие или более. Новая задача заключается в том, как защитить текстовые данные, которые сейчас востребованы для генеративного ИИ?
Большие языковые модели (LLMS) основаны на широко доступном и публичном тексте, а предприятия добавят ценность авторитетной базой знаний, основанной на документах частных предприятий (поддержка билетов, документы Word и т. Д.). Эти документы отражают знания в контексте и включены в генеративный ИИ путем создания получения добычи (RAG).
Генеративное решение AI на основе RAG включает текстовые данные, включая билеты на поддержку, каталоги продуктов, в документах House Word, PDFS и других источниках. Эти данные должны быть очищены от личной информации (PII), так как данные PII не могут быть просочены к клиенту, обращенному к генеративному приложению ИИ!
Векторная база данных становится авторитетной базой знаний и запрашивается LLM в реагировании на подсказки клиентов. Этот генеративный ИИ, основанный на тряпке, является самым популярным подходом к ИИ предприятия.
Генеративный ИИ, основанный на тряпке, является наиболее распространенным подходом к генеративному ИИ предприятия. Генеративный ИИ быстро развивается, и одна область, которая привлекает внимание,-это необходимость в практически в реальном времени, которая обычно хранится в базах данных. Различные методы включения реляционных данных включают структурирование генеративного приложения ИИ для исходных данных с помощью запросов SQL или определение конкретных запросов в векторной базе данных, чтобы искать явно связанные данные для доставки через генеративное приложение AI.
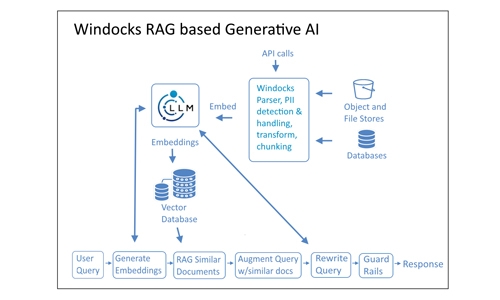
Это изображение иллюстрирует поток информации от необработанных документов до информации, которая может быть извлечена из приложения на основе LLM.
Ключевые преимущества синтетических данных
Смоделированные синтетические данные смотрят и ощущаются как исходные данные
Маскированные и анонимные данные включают замену первичных идентификаторов, таких как «Джон Смит», замененный «Тоби Джонс». Полученные данные являются анонимизированными, но не отражают межколонные корреляции, такие как возраст с доходом, географическое распределение и другие нюансы исходных данных.
Моделированные синтетические данные отражают распределения исходных данных, заполняя конфиденциальные данные значениями, которые выглядят как источник. Результатом является более высокое качество и полезность в защищенных данных, которые можно использовать для аналитики или использовать для увеличения наборов данных машинного обучения с высокой точностью данных.
Синтетические данные обеспечивают гарантированную конфиденциальность и соответствие данных
Маскированные и анонимные базы данных подлежат атакам сцепления, где анонимные данные соединены с другим набором данных для повторных идентификаторов. Существует много примеров атак сцепления, в том числе данных о здравоохранении, и даже публичный конкурс, включающий рекомендации фильма Netflix.
Чтобы избежать этих проблем, Microsoft, Amazon и другие обращаются к синтетически заполненным данным с дифференциальной конфиденциальностью для математически гарантированной конфиденциальности данных. Дифференциальная конфиденциальность - это математическое решение, которое включает в себя достаточный шум в результатах запроса, чтобы гарантировать, что ни один человек не может быть идентифицирован из синтетически заполненного набора данных.
Точность синтетических данных необходима для машинного обучения и генеративного искусственного интеллекта на основе Generative AI
Соответствие данных с GDPR, CCPA и другими правовыми стандартами не ограничивается табличными и реляционными данными, но включает в себя личные данные в билетах поддержки, текстовых файлах, документах, PDF и журналах. Современные растворы синтетических данных считывают и обнаруживают конфиденциальные текстовые данные в ведрах S3, Blobs Azure и хранилищах файлов, и либо отредактируют, либо заменяют конфиденциальные данные синтетическими данными.
Стратегия конфиденциальности синтетических данных, применяемая к документам и базам данных, является наилучшей практикой для конфиденциальности и соответствия, но также поддерживает бизнес -императив для защищенных конфиденциальности данных для разработки крупных языковых моделей (LLMS) и генеративного искусственного интеллекта.






