






Обучение ChatGPT на собственных данных

Интерактивное чтение с помощью MEMWALKER расширяет возможности моделей искусственного интеллекта, делая диалоги более насыщенными и контекстно-зависимыми, расширяя границы возможностей современного искусственного интеллекта.
Запуск ChatGPT от OpenAI изменил развитие диалогового ИИ. Несмотря на впечатляющие возможности ChatGPT, возможности ChatGPT по своей сути ограничены фиксированными данными обученияс 2021 года. Для разработчиков программного обеспечения и технологических компаний обучение ChatGPT на пользовательских наборах данных является ключом к созданию индивидуальных помощников искусственного интеллекта, которые развиваются вместе с вашим бизнесом.
В этом подробном руководстве разработчики компании DST Globalрассмотрят передовые методы для групп разработчиков программного обеспечения по обучению индивидуальных моделей ChatGPT с использованием таких методов, как точная настройка и интерактивное чтение MEMWALKER.
Преодоление ограничений обучения ChatGPT по умолчанию
Вкратце: ChatGPT был предварительно обучен OpenAI на огромном наборе данных общих знаний, включая Википедию, книги, веб-сайты и многое другое. Однако, поскольку эти данные обучения были заморожены в 2021 году, у ChatGPT есть некоторые естественные недостатки:
- Отсутствие осведомленности о недавних событиях или новых темах после 2021 года.
- Узкая экспертиза за пределами общих областей, таких как история и литература.
- Никаких личных способностей памяти, основанных на разговорах.
- Трудно поддерживать контекст в длинных диалогах.
Эти ограничения возникают непосредственно из фиксированного набора данных ChatGPT, в котором отсутствуют актуальные специализированные знания. Обучая ChatGPT на собственных тщательно отобранных данных, вы можете создать версию, адаптированную к вашей отрасли, тематике и бизнес-потребностям.
Ключевые подходы к обучению моделей ChatGPT
Существует несколько основных методов, которые команды разработчиков программного обеспечения могут использовать для настройки ChatGPT:
Точная настройка курируемых наборов данных
Один из простых подходов — сбор соответствующих текстов, таких как документы, электронные письма, руководства и т. д., для точной настройки модели ChatGPT. Процесс включает в себя:
- Составление пользовательского набора данных: соберите тексты, охватывающие темы и знания, которые вы хотите изучить ChatGPT.
- Очистка и предварительная обработка: приведите данные в стандартный формат. Анонимизируйте любую конфиденциальную информацию.
- Точная настройка модели: используйте API, такой как Anthropic, для загрузки набора данных и дальнейшего обучения ChatGPT посредством обратного распространения ошибки.
Точная настройка напрямую привносит ваши отраслевые знания в ChatGPT.
Интерактивное чтение с MEMWALKER
Для длинного текста передовые методы, такие как MEMWALKER, позволяют более эффективно обрабатывать контекст во время обучения. MEMWALKER имеет две фазы:

Построение дерева памяти: длинные тексты разбиваются на сегменты. Каждый сегмент сводится к узлам, образующим древовидную структуру.
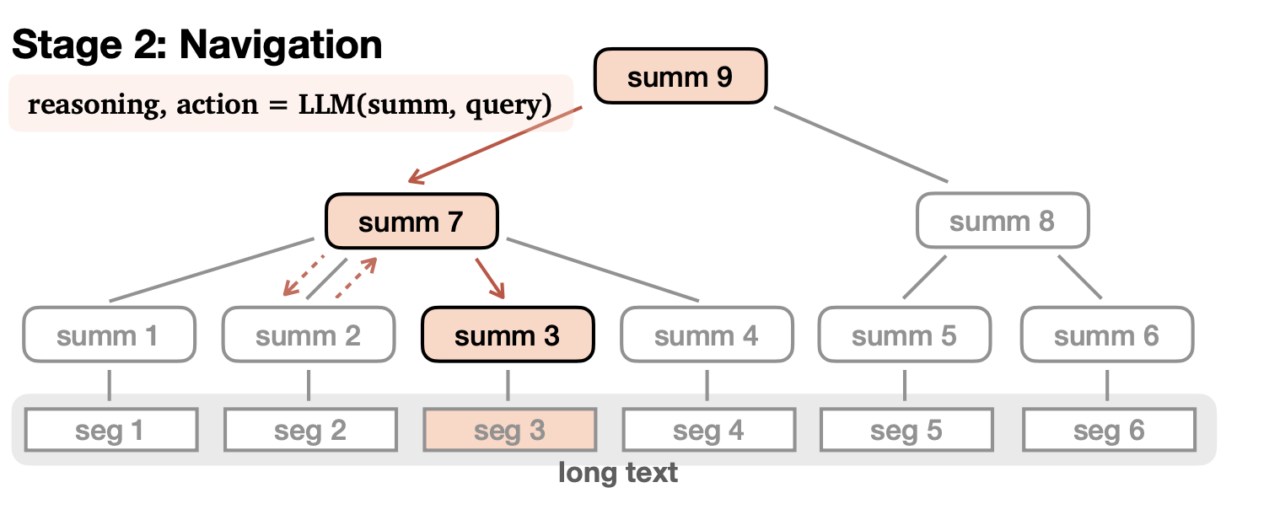
- Навигация по дереву: отвечая на вопрос, ИИ обходит дерево, чтобы собрать важные сведения из узлов.
Этот подход позволяет сохранять контекст в длинных примерах.
Поисковое увеличение
Вы также можете использовать расширение поиска, индексируя свой набор данных и комбинируя поиск с ChatGPT. Это позволяет использовать большие объемы нишевых данных во время вывода.
- Создайте векторный индекс: индексируйте свою собственную текстовую коллекцию для семантического поиска.
- Интеграция поиска: при запросе ChatGPT сначала извлекайте релевантные тексты из индекса.
- Генерация ответов. Пусть ChatGPT использует эти тексты для предоставления ответов.
Вместе эти методы позволяют существенно настраивать знания ChatGPT. Далее мы рассмотрим шаги по обучению вашей собственной модели.
Собираем все вместе: как тренировать ChatGPT
Давайте рассмотрим практическое руководство по обучению вашей собственной модели ChatGPT, адаптированной к вашему сценарию использования:
1. Соберите и подготовьте данные для обучения
- Соберите разнообразный набор данных текстового контента, связанного с вашей отраслью или темами. Собирайте соответствующие веб-сайты, собирайте документацию по продуктам, создавайте собственные статьи и т. д.
- Очистите данные, исключив дубликаты текстов, исправив проблемы с форматированием и анонимизировав любую личную информацию.
- Разделите набор данных на обучающее, проверочное и тестовое подмножества.
2. Загрузите свои данные на платформу искусственного интеллекта.
- Используйте такую платформу, как Anthropic или Cohere, для загрузки своих наборов данных. Обязательно правильно маркируйте разделения данных.
- В качестве базовой выберите архитектуру модели ChatGPT, например Claude, или модель GPT-3.
3. Проведите дополнительное обучение
- Точная настройка базовой модели для вашего тренировочного разделения с помощью тренировки градиентного спуска. Проверьте свой набор разработчиков.
- Рассмотрите возможность использования таких методов, как MEMWALKER, для длинных текстов.
- Для поиска можно индексировать тексты и интегрировать семантический поиск.
4. Оцените своего индивидуального чат-бота
- Проверьте свою специально обученную модель на тестовом наборе и в реальных разговорах.
- Проанализируйте запоминаемость модели ключевых понятий, актуальность и связность разговора.
- Итеративно совершенствуйтесь, собирая больше данных о слабых сторонах и проводя переобучение.
5. Разверните свою модель
- Если все устраивает, разверните свой собственный ChatGPT с помощью API, предлагаемых платформами искусственного интеллекта.
- Настройте производственные экземпляры и интегрируйте их в свои приложения и рабочие процессы бизнеса.
- Контролируйте и поддерживайте модель, переобучая ее по мере необходимости на новых данных.
Реальные применения пользовательских чат-ботов
Для специально обученных моделей ChatGPT в бизнесе открываются безграничные возможности:
- Боты поддержки клиентов: обучайтесь документации по продуктам, руководствам и ответам на распространенные вопросы.
- Боты для отраслевого анализа: собирайте отчеты о доходах, пресс-релизы и статьи для ответов на финансовые вопросы.
- Боты-эксперты по предметам: преподают медицину, право, инженерное дело и т. д., обучаясь по учебникам и исследовательским работам.
- Боты корпоративной культуры: помогают новым сотрудникам принимать на работу, обучая их внутренним вики-сайтам, справочникам и истории обмена сообщениями.
Как видите, практически любая отрасль или ниша могут получить выгоду от индивидуального и знающего помощника ChatGPT. Эта настройка открывает гораздо больше возможностей для общения, соответствующих вашим сценариям использования.
Сфера интерактивного чтения предлагает множество практических приложений. Возьмем, к примеру, расширенную генерацию поиска ( RAG ), которая объединяет поиск с генерацией текста. Такие модели могут значительно выиграть от MEMWALKER, позволяя им эффективно извлекать соответствующую информацию из обширных коллекций документов.
Кроме того, компании могут использовать возможности пользовательских чат-ботов с искусственным интеллектом, интегрированных с MEMWALKER. Это гарантирует, что их чат-боты смогут вести более широкие и естественные разговоры, сохраняя при этом необходимый контекст.
С продолжающимся развитием моделей большого языка (LLM) потенциал интерактивного чтения только расширяется. Это открывает путь ИИ к умелому управлению задачами, требующими глубокого понимания контекста, памяти и логического рассуждения.
Будущее обучения больших моделей искусственного интеллекта
Такие методы, как интерактивное чтение, указывают на более человечную обработку контекста в больших языковых моделях. Поскольку LLM становятся все больше, сокращение их потребности в данных будет иметь решающее значение. Эффективное кодирование информации также позволяет использовать более специализированные нишевые знания.
Для команд-разработчиков программного обеспечения обучение эффективному обучению и настройке таких моделей, как ChatGPT, открывает огромные возможности. В сочетании с такими методами, как расширение поиска, мы неуклонно движемся к созданию ИИ-помощников, которые могут вести содержательные и глубокие беседы, охватывающие широкий спектр тем. Впереди захватывающие времена: модели продолжают становиться умнее!
Разработчики DST Global надеются, что это руководство пролило свет на эффективные методы обучения вашего собственного бота ChatGPT. Имея правильные данные и эффективные подходы к обучению, вы можете создать диалоговых агентов, специализирующихся на вашем бизнесе по разработке программного обеспечения и разработчиках.






