






Как унифицированные конвейеры обработки данных трансформируют современную инфраструктуру ИИ

В настоящее время ИИ использует разнообразные типы данных, и старые конвейеры обработки данных испытывают трудности. Единые потоки данных централизуют данные, упрощая управление и улучшая обучение и производительность моделей.
Со временем темпы совершенствования моделей ИИ опередили темпы развития конвейеров, предназначенных для их поддержки. Команды переходят к более сложным сигналам и большим объемам работы, но конвейерам становится все сложнее это поддерживать. Этот разрыв увеличивается с каждым новым источником данных, добавляемым в эту систему, вынуждая инженеров объединять рабочие процессы, которые изначально не были предназначены для совместной работы.
Производительность снижается, количество итераций уменьшается, и теперь система начинает ограничивать те самые модели, для поддержки которых она и была создана. Эта проблема решается за счет унифицированного потока данных, который обеспечивает масштабируемую структуру ИИ. В разделах ниже будут подробно рассмотрены ключевые моменты, объясняющие важность этого изменения.
Многоформатные данные как новый стандарт
Современные модели ИИ собирают данные из источников, которые не похожи друг на друга, поступают с разной скоростью и имеют совершенно разные структуры данных. Сейчас команды смешивают визуальные сигналы с текстом, машинный вывод с контентом, созданным человеком, а также потоки данных, привязанные ко времени, со статическими артефактами.
Диапазон постоянно расширяется, и каждая категория вносит новые ограничения, которые влияют на производственный процесс. Традиционные конвейеры больше не справляются с разнообразием, которое требует эта современная модель. Кроме того, эта модель создает ряд новых проблем, таких как:
Форматы, требующие различных стратегий подготовки перед обучением.
Входные данные, значительно различающиеся по размеру, времени обработки, сложности и другим характеристикам.
Согласование рабочих процессов становится все более сложной задачей, поскольку каждый источник выбирает свой собственный путь.
Единые потоки данных позволяют командам управлять всеми своими данными в рамках единого согласованного конвейера, вместо того чтобы иметь дело с разрозненными процессами, которые плохо взаимодействуют друг с другом.
Где традиционные трубопроводы выходят из строя
Традиционные конвейеры обработки данных были разработаны для рабочих нагрузок, которые казались однородными и предсказуемыми. Они предполагали постоянный поток входных данных со схожей структурой, временными параметрами и потребностями в предварительной обработке. Но по мере того, как команды начинают работать с более широким набором источников данных, все эти предположения рушатся.
Каждая категория заставляет конвейер работать по-разному, что, в свою очередь, приводит к различным путям выполнения кода, обработке особых случаев и схемам хранения данных, которые перестают быть единой интегрированной системой.
Со временем эти различия создают трения, которые замедляют экспериментирование и затрудняют интерпретацию результатов моделирования. Слабые стороны, как правило, проявляются на практике, например:
Конвейеры, которые разделяются на треки, специфичные для каждого формата, и которые никогда не совпадают идеально.
Логика предварительной обработки данных разрабатывается в разных командах и с использованием различных инструментов.
Метаданные становятся непоследовательными, что нарушает последующие этапы обработки.
По мере расширения масштабов проектов и использования более широкого спектра входных данных, команды сталкиваются с трудностями. В результате устаревшие конструкции со временем становятся ограничивающим фактором, а не фактором поддержки.
Почему важны унифицированные потоки данных
Единые потоки данных предоставляют командам механизм для управления различными входными данными, не оставляя их в лабиринте отдельных, независимых рабочих процессов. Другими словами, вместо работы с инструментами, специфичными для каждого формата, этот конвейер применяет согласованный набор структурных требований ко всем источникам.
Это обеспечивает согласованный поток данных, что снижает трение на этапах сбора, подготовки и доставки. В свою очередь, это гарантирует, что модели смогут получать доступ к данным в формате, облегчающем стабильное обучение. Единый подход значительно упрощает развитие конвейера обработки данных с течением времени, поскольку изменения происходят в одном месте, а не в разрозненных подсистемах. Несколько преимуществ, определяющих ценность унификации, следующие:
Более тесная согласованность между этапами подготовки, независимо от происхождения.
Меньшие инженерные затраты благодаря повторяющейся логике.
Более предсказуемое поведение во время обучения и вывода результатов.
Этот подход демонстрирует, как современные платформы, такие как Apache Spark , Ray и Daft, поддерживают многомодальные рабочие нагрузки в рамках единой модели выполнения, а не рассматривают различные режимы как отдельные системы.
Основные компоненты современного трубопровода
Современный конвейер обработки данных справляется с вариативностью, создавая стабильную структуру, которую может обработать каждый входной параметр. Эта структура не устраняет различия между форматами, но обеспечивает путь, который их поглощает без необходимости использования отдельных рабочих процессов.
Каждый этап вносит свой вклад в структуру, которая остается предсказуемой, несмотря на появление новых источников, новых инструментов или требований к модели.
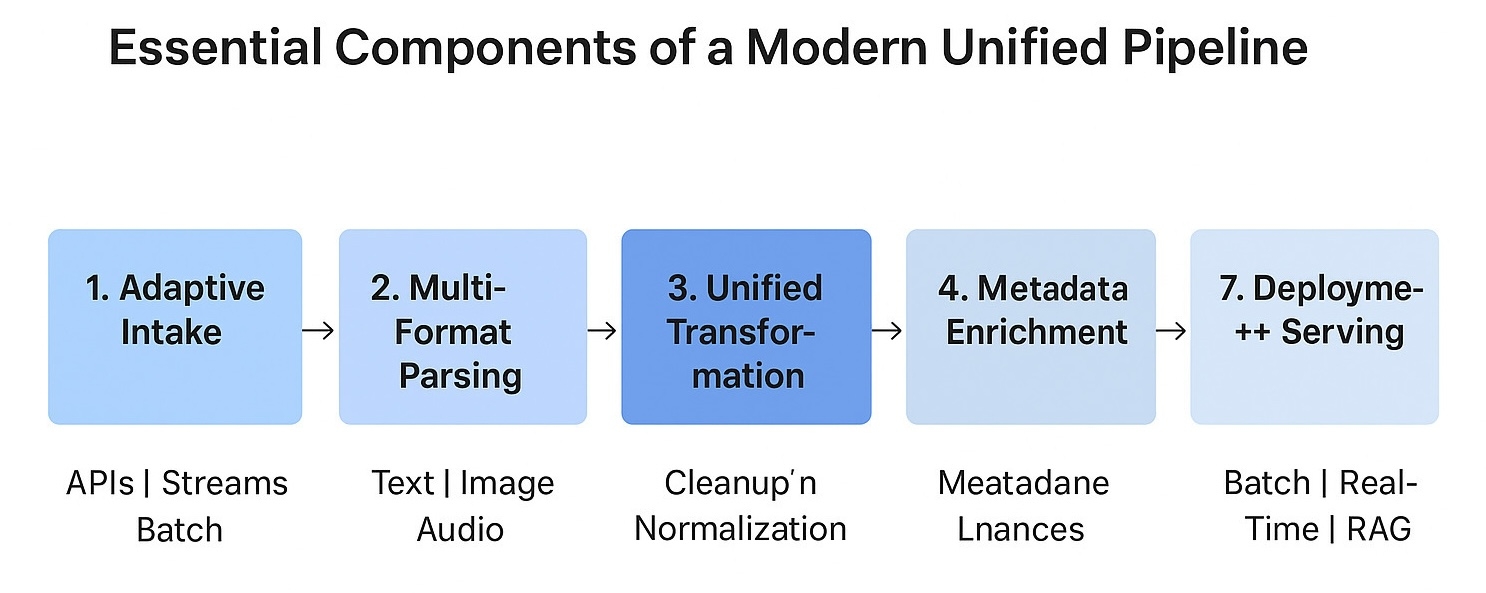
1. Адаптивные входные слои : эти компоненты принимают данные из различных источников и преобразуют их в форму, которая может быть обработана конвейером обработки данных без необходимости перезаписи какого-либо специфического формата.
2. Этапы извлечения данных из разных форматов : исходные данные анализируются и преобразуются таким образом, чтобы последующие этапы получали согласованную структуру, даже если источники значительно различаются.
3. Единая логика преобразования : набор общих правил для нормализации, очистки и формирования, который предотвращает расхождения между модальностями и стабилизирует поведение модели.
4. Надежная обработка метаданных : контекст остается неизменным на протяжении всего рабочего процесса, предоставляя моделям всю необходимую информацию для правильной интерпретации каждого выходного результата.
Эти компоненты работают вместе, поддерживая конвейер, который может расти и развиваться в соответствии с четко определенными границами.
Как унифицированные потоки улучшают качество модели
Модели выигрывают, когда входные данные поступают в форме, отражающей согласованную подготовку и временные параметры. Единый поток данных обеспечивает согласованность, при которой все источники обрабатываются в одной и той же последовательности проверок, этапов формирования и маршрутизации. Вариации, наблюдавшиеся из-за предварительной обработки, специфичной для формата, начинают исчезать, что усиливает сигналы, на которые модели опираются во время обучения.
Там, где раньше были противоречивые или несогласованные входные данные, теперь они поддерживают друг друга, что, в свою очередь, улучшает представление и структуру модели. Кроме того, по мере оптимизации рабочих процессов команд, наличие согласованных потоков становится скорее фактором повышения производительности, чем препятствием.
В настоящее время некоторые организации используют Daft для управления различными входными данными с помощью единого конвейера. Это позволяет снизить нагрузку, создаваемую разрозненными рабочими процессами.
Операционные успехи инженерных команд
Единые потоки данных представляют собой отправную точку, а не конечную цель для современных систем искусственного интеллекта. По мере того, как модели становятся все более сложными и зависят от более разнообразных комбинаций входных данных, требования к инфраструктуре, вероятно, будут только расти. Конвейеры, которые корректно обрабатывают вариативность, определят направление построения моделей в следующем поколении.
В центре внимания оказывается среда, которая интегрирует новые типы данных без необходимости масштабной переработки и масштабируется в рамках единой, согласованной структуры. Организациям, которые внедрят новые технологии на раннем этапе, будет проще поддерживать сложные рабочие нагрузки и идти в ногу со скоростью развития ИИ.
Перспективы развития унифицированной инфраструктуры искусственного интеллекта
Единые потоки данных становятся определяющей чертой современной инфраструктуры ИИ . Они предлагают оптимизированную архитектуру, которая заменяет разрозненные рабочие процессы гибкой структурой, способной вмещать дополнительные источники данных, объемы и сложность.
Команды получают стабильность, более четкие пути масштабирования и основу, поддерживающую более быструю разработку. По мере роста сложности ИИ, конвейеры, построенные на основе единого потока, будут определять подход компаний к выполнению наиболее важных задач.






